While working with small datasets, Pandas is typically the best option, but when it comes to larger ones, Pandas doesn’t suffice as it loads all the data into a single machine for processing. With large datasets, you will need the power of distributed computation. In such a situation, one of the ideal options available is PySpark – but this comes with a catch. PySpark syntax is complicated to both learn and to use.
This is where the Koalas package introduced within the Databricks Open Source environment has turned out to be a game-changer. It helps those who want to make use of distributed Spark computation capabilities without having to resort to PySpark APIs.
This blog discusses in detail about the key features of Koalas, and how you can optimize it using Apache Arrow to suit your requirements.
Introducing Koalas
Simply put, Koalas is a Python package that is similar to Pandas. It performs computation with Spark.
Features:
1. Koalas is lazy-evaluated like Spark, i.e., it executes only when triggered by an action.
2. You do not need a separate Spark context/Spark session for processing the Koalas dataframe. Koalas makes use of the existing Spark context/Spark session.
3. It has an SQL API with which you can perform query operations on a Koalas dataframe.
4. By configuring Koalas, you can even toggle computation between Pandas and Spark.
5. Koalas dataframe can be derived from both the Pandas and PySpark dataframes.
Following is a comparison of the syntaxes of Pandas, PySpark, and Koalas:
Versions used:
Pandas -> 0.24.2
Koalas -> 0.26.0
Spark -> 2.4.4
Pyarrow -> 0.13.0
Pandas:
import Pandas as pddf = pd.DataFrame({‘col1’: [1, 2], ‘col2’: [3, 4], ‘col3’: [5, 6]})
df[‘col4’] = df.col1 * df.col1
Spark
df = spark.read.option(“inferSchema”, “true”).option(“comment”, True).csv(“my_data.csv”)df = df.toDF(‘col1’, ‘col2’, ‘col3’)
df = df.withColumn(‘col4’, df.col1*df.col1)
Now, with Koalas:
import databricks.Koalas as ksdf = ks.DataFrame({‘col1’: [1, 2], ‘col2’: [3, 4], ‘col3’: [5, 6]})
df[‘col4’] = df.col1 * df.col1
You can use the same Pandas syntax for working with Koalas, for computing in a distributed environment as well.
Optimizations that can be performed using Koalas
1. Pandas to Koalas Conversion Optimization Methods:
Three different optimizations for the Pandas-to-Koalas conversion are discussed below. The last two methods make use of Apache Arrow, which is an intermediate columnar storage format, that helps in faster data transfer.
a) Pandas to Koalas conversion (Default method):
We can directly convert from Pandas to Koalas by using the Koalas.from_Pandas() API.

b) Pandas to Koalas conversion (With implicit Apache Arrow):
Apache arrow is a development platform for in-memory analytics. It contains a set of technologies that enable big data systems to process and move data fast. It specifies a standardized, language-independent, columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware.
To install:
pip install pyarrow
This method of optimization can be done by setting the spark.sql.execution.arrow.enabled to true as shown below:
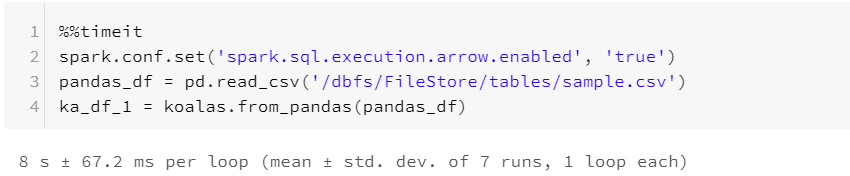
c) Pandas to Koalas conversion (With explicit Apache Arrow):
This optimization involves converting Pandas to the Arrow table explicitly and then converting that to Koalas.
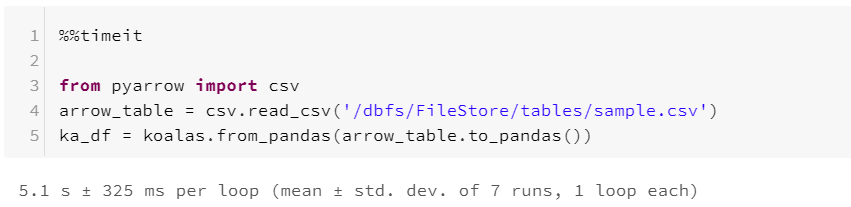
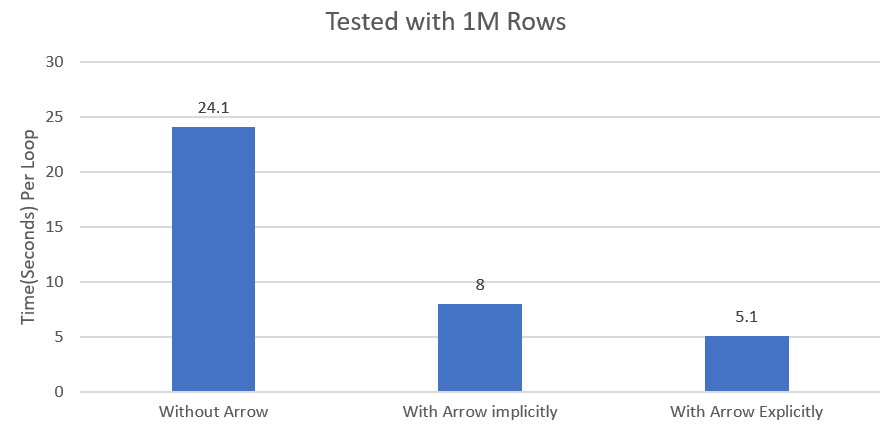
Benchmarking Conversion Optimization Techniques
As seen above, using Arrow explicitly in the conversion method is a more optimized way of converting Pandas to Koalas. This method becomes even more helpful if the size of the data keeps increasing.
2. Optimization on Display Limit:
To set the maximum number of rows to be displayed, the option display.max_rows can be set. The default limit is 1000.
Koalas.set_option(‘display.max_rows’, 2000)
3. Optimization on Computation Limit:
Even the computation limit can be toggled based on the row limit, by using compute.shortcut_limit. If the row count is beyond this limit, computation is done by Spark, if not, the data is sent to the driver, and computation is done by Pandas API. The default limit is 1000.
Koalas.set_option(‘compute.shortcut_limit‘, 2000)
4. Using Option context:
With option context, you can set a scope for the options. This can be done using with command.
with Koalas.option_context(“display.max_rows”, 10, “compute.max_rows”, 5):
… print(Koalas.get_option(“display.max_rows”))
… print(Koalas.get_option(“compute.max_rows”))
10
5
print(Koalas.get_option(“display.max_rows”))
print(Koalas.get_option(“compute.max_rows”))1000
1000
There are a few more options available here
5. Resetting options:
You can simply reset the options using reset_option.
Koalas.reset_option(“display.max_rows”)
Koalas.reset_option(“compute.max_rows”)
Conclusion:
Since Koalas uses Spark behind the scenes, it does come with some limitations. Do check that out before incorporating it. Being a Pandas developer, if your sole purpose of using Spark is for distributed computation, it is highly recommended to go with Koalas.
Note: This benchmarking was done using a Databricks machine (6GB,0.88 cores).




