Introduction
As Data Scientists, one of the most pressing challenges we have is how to operationalize machine learning models so that they are robust, cost-effective, and scalable enough to handle the traffic demand. With advanced cloud technologies and serverless computing, there are now cost-effective (pay based on usage) and auto-scalable platforms (with scale-in/scale-out architecture depending on the traffic) available. Data scientists can use these to accelerate the machine learning model deployment without having to worry about the infrastructure.
This blog discusses one such methodology of implementing the machine learning code and model developed locally using Jupyter notebook in the Azure environment for real-time predictions.
ML Implementation Architecture
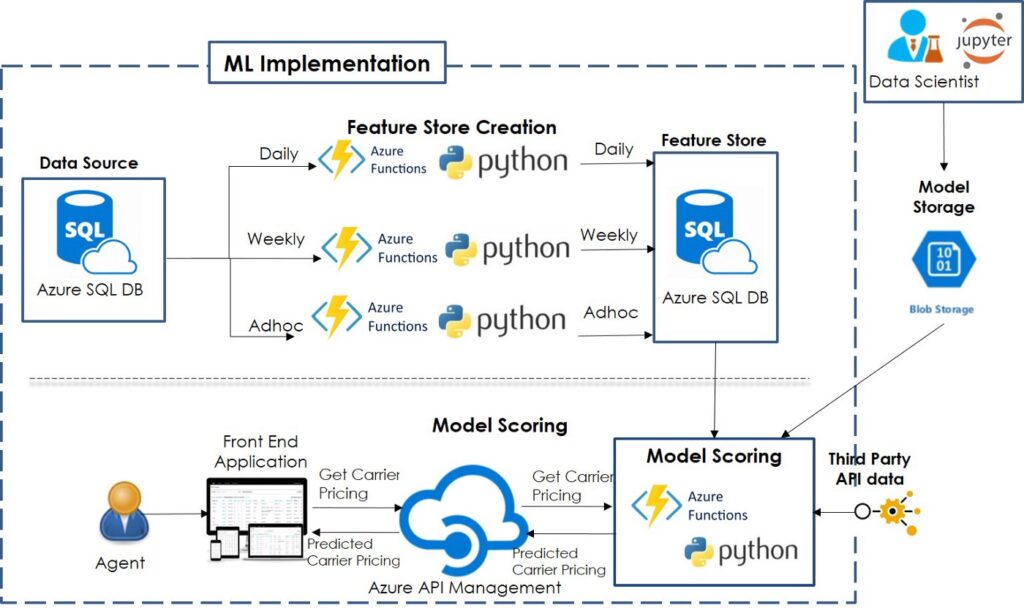
ML Implementation Architecture
We have used Azure Functions to deploy the Model Scoring and Feature Store Creation codes into production. Azure Functions is a FaaS offering (Function as a Service or FaaS provides event-based, serverless computing to accelerate development without having to worry about the infrastructure). Azure Functions comes with some interesting functionalities like-
1. Choice of Programming Languages
You can work with any language of your choice- C#, Node.js, Java, Python
2. Event-driven and Scalable
You can use built-in triggers and bindings such as http trigger, event trigger, timer trigger, and queue trigger to define when a function is invoked. The architecture is scalable, depending on the workload.
ML Implementation process
Once the code is developed, the following are the best practices to make the machine learning code production-ready. Below are the steps to deploy the Azure Function.
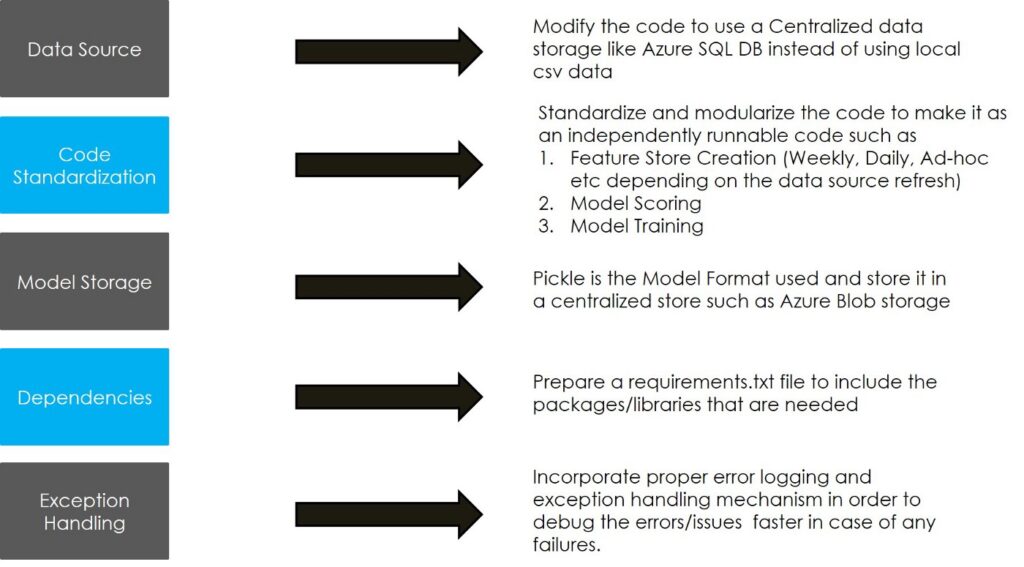
ML Implementation Process
Azure Function Deployment Steps Walkthrough
Visual Studio Code editor with Azure Function extension is used to create a serverless HTTP endpoint with Python.
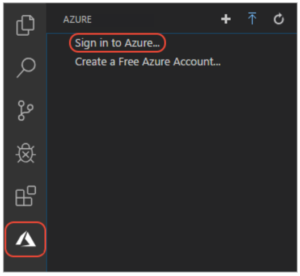
1. Sign in to Azure
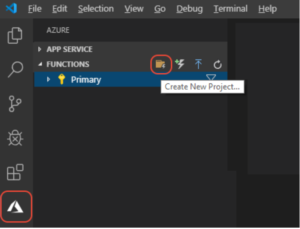
2. Create a New Project. In the prompt that shows up, select the Language as Python, Trigger as http trigger (based on the requirement)
3. Azure Function is created, and the folder structure is as follows. Write your logic or copy the code if already developed into __init__.py
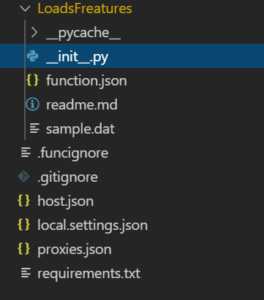
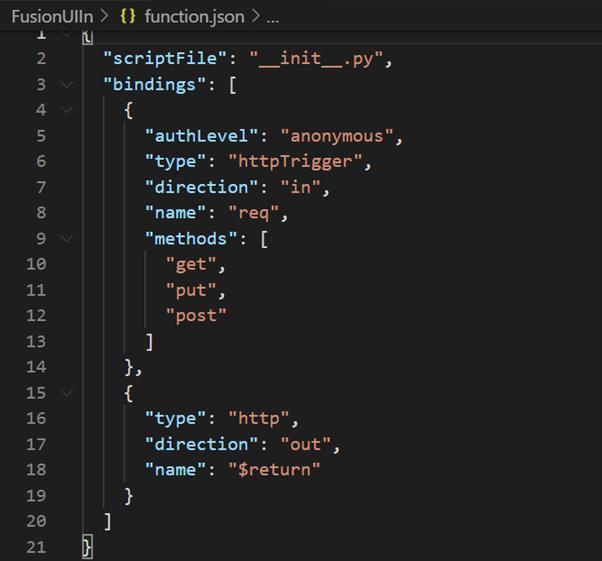
4. function.json, triggered by http trigger, defines the bindings in this case
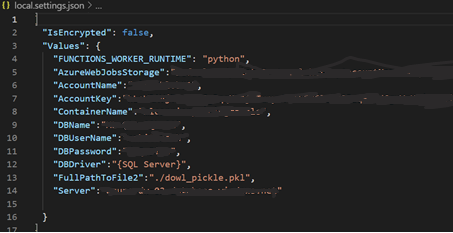
5. local settings.json contains all the environmental variables used in the code as a key-value pair
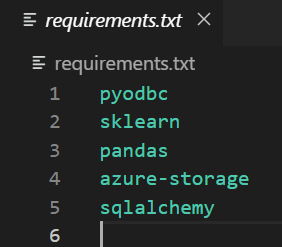
6. requirements.txt contains all libraries that need to be pip installed
7. As the model is stored in Blob, add the following line of code to read from Blob
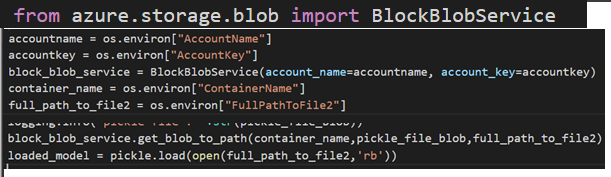
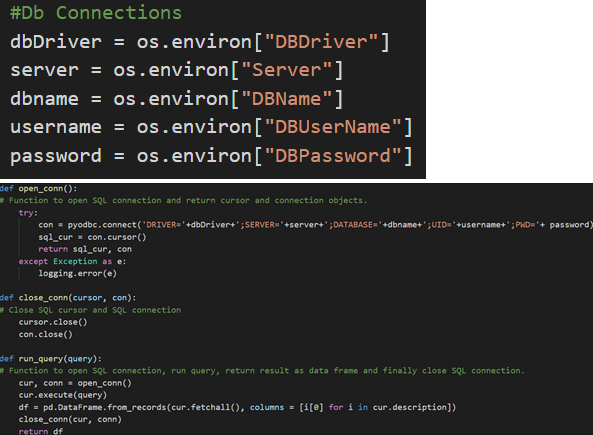
8. Read the Feature Store data from Azure SQL DB
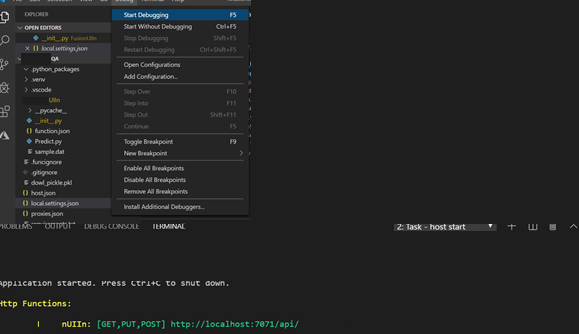
9. Test locally. Choose Debug -> Start Debugging; it will run locally and give a local API endpoint
10. Publish to Azure Account using the following
func azure functionapp publish functionappname functionname — build remote — additional-packages “python3-dev libevent-dev unixodbc-dev build-essential libssl-dev libffi-dev”

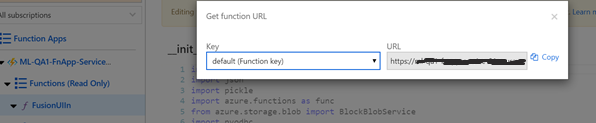
11. Log in to Azure Portal and go to Azure Functions resource to get the API endpoint for Model Scoring
Conclusion
This API can also be integrated with front-end applications for real-time predictions.
Happy Learning!




