Introduction
This article focuses on giving a detailed explanation of how one can reduce the latency for I/O bound operations. More often than not, we see an increased latency when we read/write data to a disk, network, or any modes of data storage. This latency is due to the time spent waiting for input/output operations to complete. Keeping all these in mind, let us discuss a few methods to make sure we get the best “decreased latency” when reading data from the s3 bucket (for this example, the data is stored in the s3 bucket, but the same approach can also be used irrespective of where your data is stored).
Multithreading
Multithreading is the process of executing multiple threads simultaneously. Now let us check out multithreading in the context of Python. Python has numerous libraries. When it comes to multithreading, one of the popular libraries is ‘concurrent.futures.’ Within this library, we have important Executor subclasses called ThreadPoolExecutor, and ProcessPoolExecutor.
ThreadPoolExecutor
The ThreadPoolExecutor runs each of your workers in separate threads within the main process. This subclass of the Executor class uses multithreading and creates a pool of threads for submitting the tasks. This pool assigns tasks to the available threads and schedules them to run. The choice of the number of workers/threads is up to the user or based on the tasks.
ProcessPoolExecutor
ProcessPoolExecutor runs each of your workers in its child process. This subclass of the Executor class uses multiprocessing, and we create a pool of processes for submitting the tasks. This pool then assigns tasks to the available processes and schedules them to run.
When and Where should these Processors be Used?
If you’re dealing with an I/O bound operation, multithreading is a good option so that you can benefit from reducing I/O wait time.
If you’re dealing with CPU-bound tasks, multiprocessing is a good option so that we can get benefit from multiple CPUs.
Since we’re focussing on I/O bound operation, multithreading would outperform multiprocessing because of the below reasons-
i. For CPU bound programs, multiprocessing would be the best option and not multithreading because of Global Interpreter Lock (GIL).
ii. For I/O bound programs, multiprocessing would improve performance, but the overhead tends to be higher than when using multithreading.
Global Interpreter Lock
Global Interpreter Lock or GIL is an infamous feature of Python. It allows only one thread to hold control of the Python interpreter, meaning that only one thread can be in a state of execution at any point in time.
GIL in Multithreaded Version
In the multithreaded version, the GIL prevents the CPU-bound threads from executing in parallel. The GIL does not have much impact on the performance of I/O bound multithreaded programs as the lock is shared between threads while they are waiting for I/O.
To make this more clear, let’s have a look at the below diagram:
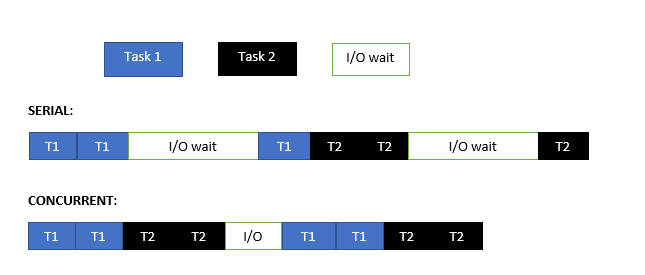
Execution of Tasks in Serial vs. Concurrent manner
If we execute it sequentially, we see that a lot of time goes into doing I/O low-level operations. Whereas in a multithreaded (concurrent) version, when thread 1 (T1) is waiting for an I/O operation to complete, it releases the GIL lock so that thread 2 (T2) can acquire it. After completion of I/O, it’ll wait for T2 to release the lock so that T1 can complete its execution. On the whole, we can see that we have reduced the time taken for the I/O wait.
In terms of CPU-bound operation, it is better to use multiprocessing instead of multithreading, because, in the end, though we use multithreading, it is considered as a single-threaded program because of GIL. If we use multiprocessing for CPU-bound threads, we’ll have our GIL interpreter for every subprocess.
Caching
Caching frequently used data is an efficient technique. Combining multithreading with caching has many implementations. Two such applications are Least Recently Used (LRU ) and Least Frequently Used (LFU). LRU will discard the least recently used data from the cache to make space for the new data, while LFU will discard the least frequently used data from the cache to make space for new data.
TTLCache
What if we need that data cached for a few minutes/hours/a whole day?
The cachetools library in Python follows LRU implementation along with a ‘time-to-live’ attribute. This helps in giving time/life for every object in the cache memory, also giving a better-decreased latency.
Examples
The following exercise has been done in ml.t2.medium instance type, wherein we have two virtual CPUs (vCPU) and 4 GB of RAM.
Files Considered
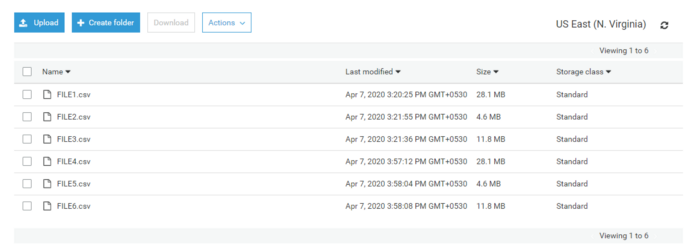
s3 location where files reside
The above image lists the sample files that are in s3. Let’s try reading those CSV files using traditional boto3 client sequentially. The below image shows the time taken to read all the three files.
import pandas as pd
import boto3
import time
import datetime#creating boto3 client
client = boto3.client(‘s3’)
bucket_name = ‘checkreadtime’
keys = [‘FILE1.csv’,’FILE2.csv’,’FILE3.csv’,’FILE4.csv’,’FILE5.csv’,’FILE6.csv’]
#function to read data from s3
def read_data_from_s3(bucket_name,key):
obj = client.get_object(Bucket=bucket_name, Key=key)
input_df = pd.read_csv(obj[‘Body’])
return input_df#USED TIME MODULE TO MEASURE THE WALL CLOCK TIME, YOU CAN USE LINE PROFILING ALSO
for key in keys:
print(key , ” Has ” , len(read_data_from_s3(bucket_name,key)) , ” Records “)
The following is the mean of the time taken from the above code after running for about 20 iterations.
Total Time Taken – 2.634592115879059
The above method takes around 2.6 seconds to read all the CSV files from s3. Do note that there are also other formats of files we can try like a feather, parquet, and so on.
Let’s try using Multithreading
import concurrent.futures
#the work function of each thread which will fetch data from s3
def download(job):
bucket, key, filename = job
s3_client = boto3.client(‘s3’)
obj = s3_client.get_object(Bucket=bucket, Key=key)
input_df = pd.read_csv(obj[‘Body’])
return input_df# We create jobs
jobs = [(bucket_name, key, key.replace(‘/’, ‘_’)) for key in keys[:]]
#make a thread pool to do the work
pool = concurrent.futures.ThreadPoolExecutor(max_workers=5)
FILE1,FILE2,FILE3,FILE4,FILE5,FILE6 = pool.map(download, jobs)
The following is the mean of the time taken from the above code after running for around 20 iterations.
Total Time Taken – 2.0443724632263183
If we see from the above two instances, we’re reducing almost 600 ms in just a few lines of code. We know that by default, threads are asynchronized. In the above results, we create a pool of 5 threads, and we assign tasks. Map function helps us in getting the synchronized results.
Let’s try Caching along with Multithreading
import cachetools.func
@cachetools.func.ttl_cache(maxsize=None, ttl=60*10)
def download(job):
bucket, key, filename = job
s3_client = boto3.client(‘s3’)
obj = s3_client.get_object(Bucket=bucket, Key=key)
input_df = pd.read_csv(obj[‘Body’])
return input_dfjobs = [(bucket_name, key, key.replace(‘/’, ‘_’)) for key in keys[:]]
#make a thread pool to do the work
pool = concurrent.futures.ThreadPoolExecutor(max_workers=5)
FILE1,FILE2,FILE3,FILE4,FILE5,FILE6 = pool.map(download, jobs)
The following is the mean time taken when we try caching and multithreading-
Total Time Taken – 0.0005709171295166015
This technique here decreases latency drastically. Here we used the decorator feature in Python to implement this caching mechanism.
Please note we can also write customized caching functions by changing the following attributes-
Maxsize — we can give the max size for cache.
Ttl — (in seconds) wherein we can pass the time for each object which is getting cached.
Conclusion
With multithreading and caching implemented correctly, we can see an improved performance in any I/O bound operations.
The process described above is one of the many ways to achieve a reduction in latency. We can tweak the same process by increasing/decreasing the number of workers in the ThreadPoolExecutor subclass to reduce the latency. One can also use other caching libraries available. Using the above illustration in real-time with the correct implementation architecture can drastically reduce the latency in an I/O bound program.



