As data scientists, we’ve all done a variety of forecasting – demand, sales, revenue, customer service calls, stock prices, bank deposits, traffic, etc. Along the same lines, can we predict the behavior of voters and, consequently, the outcome of an election? The answer is ‘Yes’ – political scientists have been doing this for a long time with varying degrees of success. In fact, this statistical analysis of elections and polls has its own niche – Psephology.
So, how do you go about predicting the outcome of an election? This article will walk you through the basic methodology, how it has evolved into today’s state-of-the-art approach, and how the Tiger Analytics team adopted and enhanced it to the Indian context.
Opinion Polls
Opinion Polls are the most widely used way of predicting elections. They are based on the fact that the preferences of a population can be estimated by studying a group of individuals. The process of identifying this group of individuals is called sampling. Statistically speaking, there are different types of sampling techniques – random, stratified, voluntary, panel, quota, cluster, etc. Different techniques get used in different contexts under various constraints.
Pollsters (those conducting the opinion poll) identify a set of respondents to be representative of the population and then interview them to understand their voting choices. In theory, if one identifies a statistically representative sample, and understands their preference, then one should be able to predict the population preference confidently – which should be the result of the election.
However, life is not that simple. A pollster’s design of their sampling methodology could result in very different samples. Similarly, the size of the sample determines the confidence in the population estimates (remember the relationship between the sample mean and the population mean?). In addition, how one asks the individual for their preference also has a bearing on whether or not their stated preference is the same as their actual preference. To complicate things further, some pollsters could have political inclinations, biasing their sample/results in favour of a particular party — attempting to subconsciously influence some voters (people like being part of the winning team).
So, while opinion polls today hold signals to what the election outcome is, they cannot be taken at face value.
Poll of Polls
A simple approach to get a more unbiased estimate of the population preference is a mean of the sample means, or in Psephology terminology, a ‘Poll of Polls’. In principle, bringing together different sample estimates helps remove biases and reduces the error margins. However, there are smarter ways to aggregate the means, than just a simple mean.
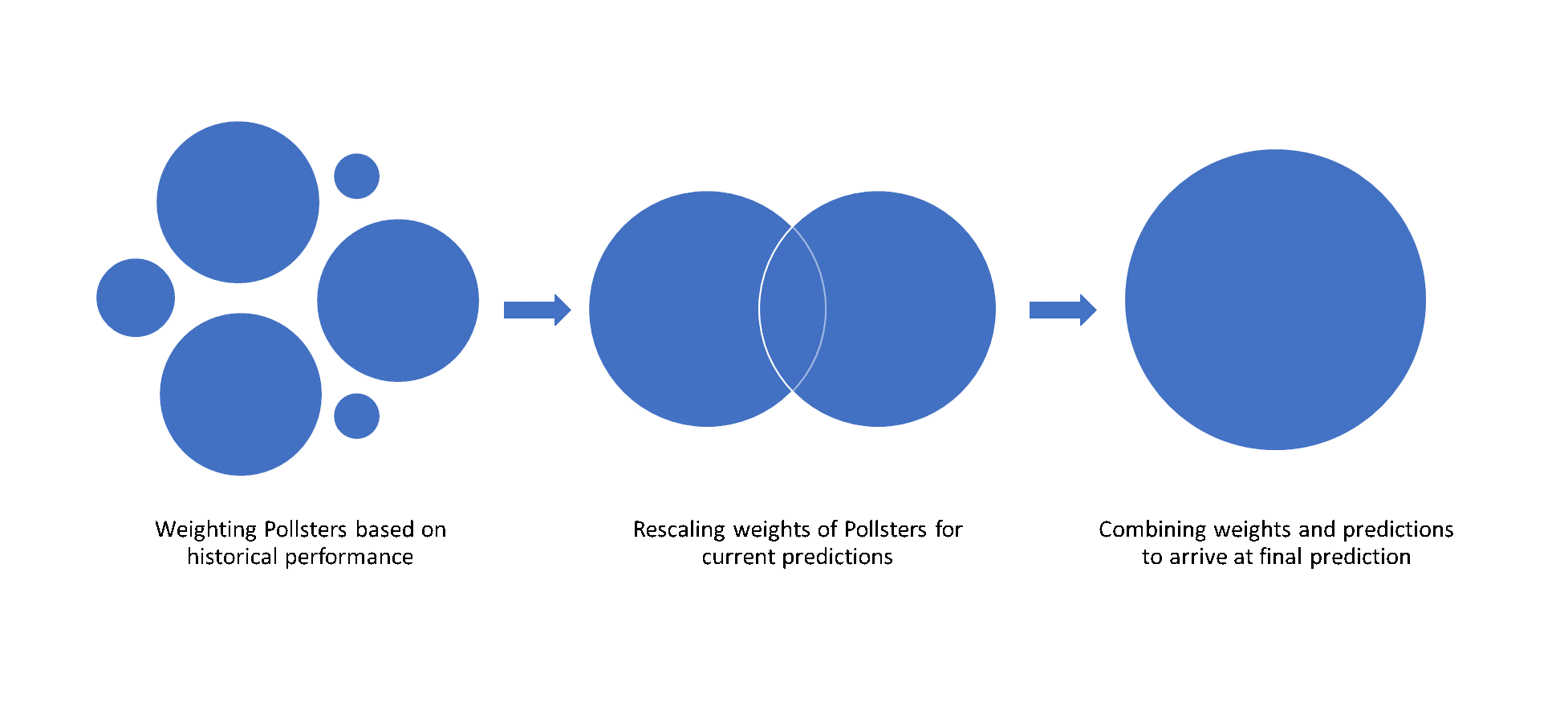
Some polls are better than others in forecasting the outcomes. We can assign a weight to each opinion poll (or pollster) depending on some key factors:
- Past Success: Past error rates of pollsters are an important indicator of their credibility in predicting the current election. Nuances such as success in different scenarios (e.g., national vs. state, large states vs. small states) can be baked in.
- Relative Performance: How a pollster performed compared to the field is also an indication of performance. This aspect is important in cases where all pollsters get the predictions wrong.
- Recency: All else being equal, the closer a poll is to the election date, the better it captures the mood of the electorate.
- Sampling methodology: Does the sampling technique used yield a representative sample? E.g. a random sample in a shopping mall would be a biased sample as opposed to dialing random phone numbers.
- Sample size: The larger the sample size of the opinion polls, the more confidence we have in the result.
The above features (and more nuanced effects) are used to arrive upon weights for each pollster. A weighted average of the seats projected by the pollsters gives the final ‘Poll of Polls’ projection corrected for observed biases.
If you’re interested to understand what the next level of details could look like, we’d encourage you to look at Nate Silver’s methodology.
Economic & Political Drivers
The above ‘Poll of Polls’ model can forecast the election results to a certain degree, but there is more that can be understood by analysing the underlying economic and political factors. You can think of a model which uses various signals to predict the results.
There are thousands of factors which could impact a voter’s behaviour, and just identifying them and finding the relevant data in itself can be an exhausting exercise. It will help if we group the factors into various categories and analyze the impact of each of these factors on outcomes.

Hypotheses need to be developed through secondary research and a bit of intuition while analyzing the impact of each of these factors. For example, while GDP is a global standard for measuring the growth of a country, its impact is not felt directly by the common man. On the other hand, even a single percentage point increase in inflation is experienced acutely by the common man.
Challenges in the Indian Context
As you’d expect, a big challenge in the Indian context (compared to the developed world) is availability of data. Data is strewn across various websites in CSV files, PDFs, plain text, etc., with lots of gaps, and collating all the data is a significant exercise in itself. Availability of data at the same level of aggregation, computed consistently, is another challenge. Missing data poses a dilemma – “go with a smaller sample or go with fewer features”, either of which would affect model performance. Tree-based ensemble models, which can handle a certain degree of missing data, can help.
Similarly, details around what and how of different opinion polls are not consistently available. Metadata such as sampling methodology, sample sizes, channels, questioning methodology, etc., are missing in several instances. It becomes a balancing act of excluding some of these from the weighting scheme vs. making intelligent assumptions where possible.
Beyond data, the multi-party system in India (as opposed to a 2-party system in the US) poses significant modeling complexity. In the 2019 general elections, the election commission reported more than 2,300 political parties (of which 150 were significant ones). We need a multinomial classification model, which has significantly higher data requirements – data, as we noted earlier, is the primary challenge. Rather than building a model for all classes, a smarter way would be to identify the right number classes so as to strike the right balance between model accuracy and efficiency. Of course, this will change by constituency.
Because of multi-party setup, India has a first-past-the-post electoral system. According to this, the winner needs to secure the highest vote share and not majority vote share. As such, the vote share needed to win an election is dependent on how many candidates are in the fray. For example, if there are only two candidates, the winner should garner more than 50% of votes. But the required vote share drops as the number of candidates increase. This is an important factor that needs to be accounted for. This can be effectively captured by a metric called Index of Opposition Unity (IOU), coined for the Indian context by Prannoy Roy and Ashok Lahiri.
Conclusion
A lesson we learnt during the process was that forecasting elections requires significant domain knowledge, just like any valuable business problem. Data is a challenge, but smart heuristics and assumptions can help significantly. And, you could be surprised about the relative impact of economic factors vis-à-vis populist actions.
Hopefully, some of this information has given you new ideas on how to analytically think about forecasting an election. Do put on this lens in your discussions with friends and colleagues as you analyze opinion polls and make your predictions for this election.




