Why is Data Transformation important?
E owns a retail business and makes their daily sales through their online and brick-and-mortar stores. Every day, they receive a huge wave of data in their systems—products viewed, orders placed, returns received, new customers, repeat customers, etc. Data ingestion pipelines help them ingest data from disparate sources. The ingested raw data pool is large and can generate valuable insights, but how do they harmonize it and turn it into actionable insights that boost the business?
That’s where Data transformation comes in.
Customers may have diverse data formats and reporting requirements, and that’s why data transformation forms a crucial aspect of any analytics product. If we examine traditional methods of manually building data transformation pipelines, we can see that these can be time-consuming and often delay the life cycle of deriving insights from data. One solution to this challenge is implementing dynamic transformation using metadata configuration. A flexible pipeline capable of adapting to data processing needs can be created by defining transformation rules and specifications.
Modernizing Data Platforms with Snowflake: Our Snowpark & Streamlit Solution
At Tiger Analytics, we created a custom solution with Snowpark and Streamlit to build dynamic data transformation pipelines based on a metadata-driven framework to accelerate data platform modernization into Snowflake. Once data is available in the raw layer, the current framework can be leveraged to build a data pipeline to transform and harmonize data in subsequent layers. The high-level architecture of this Snowpark framework is depicted below in Figure 1.
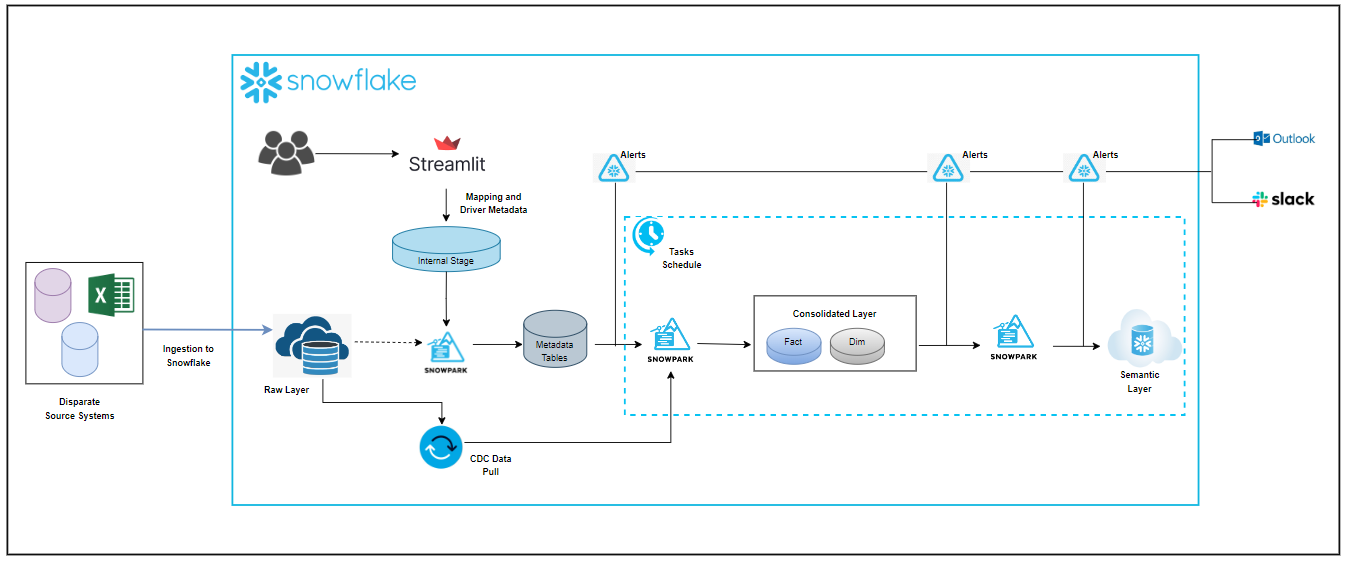
Figure 1: High-level architecture
Tiger’s Snowpark Data Transformation Framework Provides Five Key Functionalities:
- Metadata Setup
- Dynamic Transformation Pipeline Generation
- New data source, logic to be included
- Logic changes to existing pipeline
- Schedule and Execution
- Alert & Notification
- Detailed Logging
Once the data ingestion is complete, this Snowpark-based framework is leveraged by users to feed in Source to Target Mapping (STTM) and additional driver (technical) metadata (Incremental/Full Load, Schedule timing, SCD types, etc.), which drives the entire process. The input details are parsed, validated with Snowflake raw layer, and merged into metadata tables.
After the metadata setup is complete, the next Snowpark code reads the STTM metadata table and creates data transformation SQL dynamically. Based on additional driver metadata information, the Snowpark code implements change data capture (CDC) based on watermark/audit columns on top of raw layer ingested data sets, Truncate and Load, Dynamic merge/insert SQL for SCD types, etc. It is purely driven by user-provided metadata input, and any changes will be refactored in the pipeline during its generation. For this Snowpark framework, it is just a matter of a few clicks to accommodate any changes like
Snowflake Task is used to implement orchestration for data transformation pipelines. It is created dynamically using the Snowpark framework. Users can provide preferred cadence information as input, which can be referenced to create tasks dynamically with Cron schedule. Once the Tasks are created and resumed, they will automatically trigger in the scheduled cadence. As this is a metadata-driven framework, the good part is that any changes will be accommodated in the pipeline quickly.
A Snowpark-based email notification framework helps trigger emails in Outlook and Slack notifications in case of any failures observed during data transformation pipeline execution.
This Snowpark framework captures detailed logging of each step for ease of debugging. It also provides information about the pipeline execution status, which can be a key metric for other downstream modules like Observability.
This Snowpark metadata driven framework can be leveraged in any data transformation program in Snowflake to set up dynamic transformation pipelines. It can help to accelerate the overall journey and will implement the business logic efficiently, with reduced code quality issues which often arise because of human errors.
Comparing our Snowpark Framework to Other Data Transformation Pipelines
What makes our Snowpark framework unique compared to other traditional data transformation pipelines?
- Agility: Post finalization of the data model, this framework helps in faster implementation of transformation pipelines dynamically in Snowflake.
- Flexibility: Allows users to make easy modifications in the logic to adapt to the specific needs of each customer without manually changing the underlying code.
- Efficiency: Less efforts are needed to implement changes; when input metadata is changed, the pipeline gets updated.
- Auto alerts: An email is triggered based on Snowflake’s native email integration feature to alert users of any pipeline execution failures.
- Multi-feature support: Provides flexibility to enable SCD-type implementations, change data capture, and e2e detailed orchestration leveraging Snowflake Tasks.
- Pipeline Monitoring: Proper logs are maintained at each level to trace back easily in case of any issues. Proven highly impactful, reducing the overall time for the support team to debug.
- Scalability: Data volumes keep increasing. Dynamic transformation pipelines in cloud data warehouses like Snowflake can scale with the increasing demand.
- Ease of Maintenance: Simple to maintain and update as metadata changes are made directly from the Streamlit app without altering the pipeline manually.
Final thoughts
At Tiger Analytics, we created a flexible metadata-driven solution to generate dynamic data transformation pipelines. With the help of the Snowpark framework, business teams can now rapidly convert their Source-to-Target Mapping (STTM) logic into executable pipelines, significantly reducing the time to market.
The ability to quickly adapt transformation rules and handle changes through a simple, metadata-driven process ensures that businesses can harmonize raw data from multiple silos without delays, delivering faster insights and value.
With its scalability, adaptability, and ease of maintenance, this framework allows organizations to manage complex transformations effectively. In short, dynamic data transformation ensures that the data is always optimized for decision-making, empowering businesses to stay agile and competitive.




