Introduction
AWS SageMaker is a fully managed machine learning service. It provides you support to build models using built-in algorithms, with native support for bring-your-own algorithms and ML frameworks such as Apache MXNet, PyTorch, SparkML, TensorFlow, and Scikit-Learn.
Why AWS SageMaker?
- Developers or Data Scientists need not worry about infrastructure management and cluster utilization and can experiment with different things.
- Supports end-to-end machine workflow with integrated Jupyter notebooks, data labeling, hyperparameter optimization, hosting scalable inference endpoints with autoscaling to handle millions of requests.
- Provides standard machine learning models, which are optimized to run against extremely large data in a distributed environment.
- Multi-model training across multiple GPUs and leverages spot instances to lower the training cost.
Note: You cannot use SageMaker’s built-in algorithms for all the cases, especially when you have custom algorithms that require building custom containers.
This post will walk you through the process of deploying a custom machine learning model (bring-your-own-algorithms), which is trained locally, as a REST API using SageMaker, Lambda, and Docker. The steps involved in the process are shown in the image below-
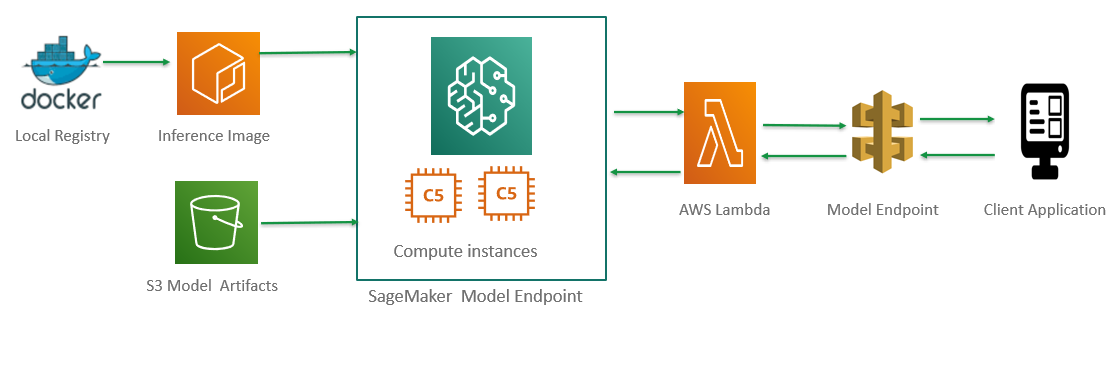
The process consists of five steps-
- Step 1: Building the model and saving the artifacts.
- Step 2: Defining the server and inference code.
- Step 3: Building a SageMaker Container.
- Step 4: Creating Model, Endpoint Configuration, and Endpoint.
- Step 5: Invoking the model using Lambda with API Gateway trigger.
Step 1: Building the Model and Saving the Artifacts
First, we have to build the model and serialize the object, which is then used for prediction. In this post, we are using simple Linear Regression (i.e., one independent variable). Once you serialize the Python object to Pickle file, you have to save that artifact (pickle file) in tar.gz format and upload it to the S3 bucket.

Step 2: Defining the Server and Inference Code
When an endpoint is invoked, SageMaker interacts with the Docker container, which runs the inference code for hosting services, processes the request, and returns the response. Containers have to implement a web server that responds to /invocations and /ping on port 8080.
Inference code in the container will receive GET requests from the infrastructure, and it should respond to SageMaker with an HTTP 200 status code and an empty body, which indicates that the container is ready to accept inference requests at invocations endpoints.
Code: https://gist.github.com/NareshReddyy/9f1f9ab7f6031c103a0392d52b5531ad
To make the model REST API enabled, you need Flask, which is WSGI(Web Server Gateway Interface) application framework, Gunicorn the WSGI server, and nginx the reverse-proxy and load balancer.
Code: https://github.com/NareshReddyy/Sagemaker_deploy_own_model.git
Step 3: Building a SageMaker Container
SageMaker uses Docker containers extensively. You can put your scripts, algorithms, and inference codes for your models in these containers, which includes the runtime, system tools, libraries, and other code to deploy your models, which provides flexibility to run your model. The Docker images are built from scripted instructions provided in a Dockerfile.

The Dockerfile describes the image that you want to build with a complete installation of the system that you want to run. You can use standard Ubuntu installation as a base image and run the normal tools to install the things needed by your inference code. You will have to copy the folder(Linear_regx) where you have the nginx.conf, predictor.py, serve and wsgi.py to /opt/code and make it your working directory.
The Amazon SageMaker Containers library places the scripts that the container will run in the /opt/ml/code/directory
Code: https://gist.github.com/NareshReddyy/2aec71abf8aca6bcdfb82052f62fbc23
To build a local image, use the following command-
docker build <image-name>

Create a repository in AWS ECR and tag the local image to that repository.
The repository has the following structure:
<account number>.dkr.ecr.<region>.amazonaws.com/<image name>:<tag>
docker tag <image-name> <repository-name>:<image-tag>

Before pushing the repository, you have to configure your AWS CLI and login


Once you execute the above command you will see something like docker login -u AWS -p xxxxx. Use this command to log in to ECR.

docker push <repository name>:<image tag>


Step 4: Creating Model, Endpoint Configuration, and Endpoint
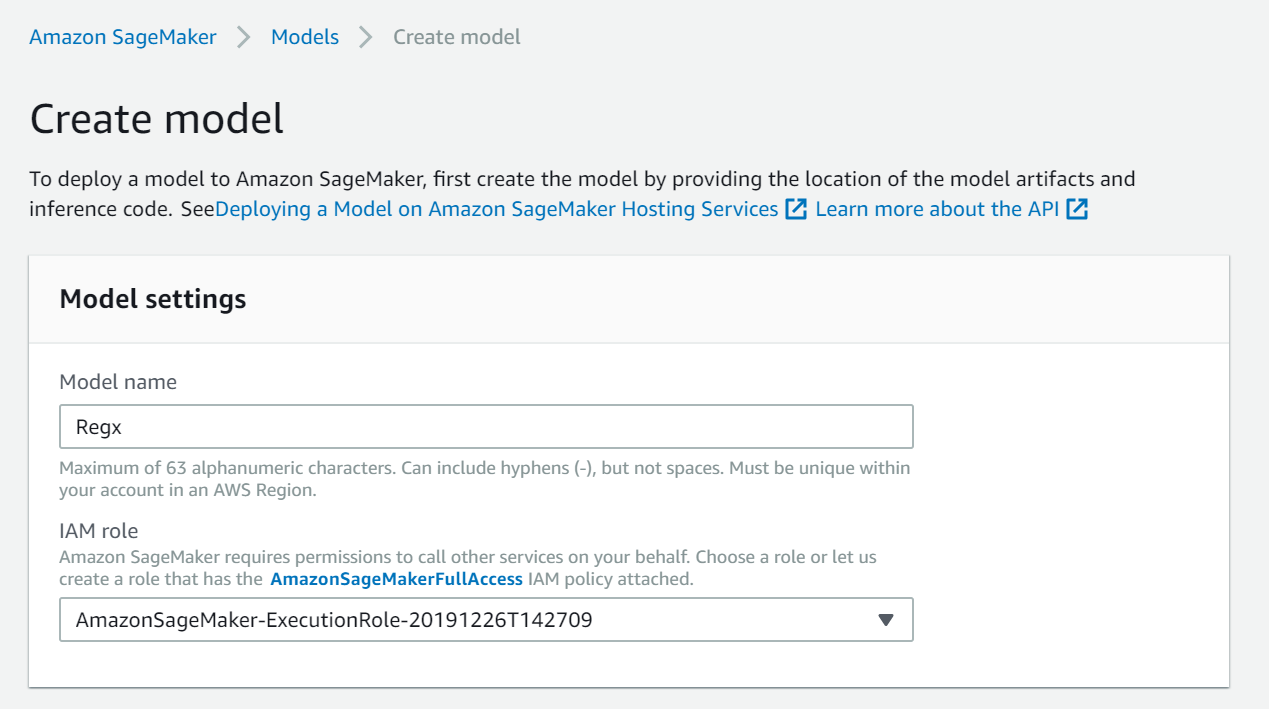
Creating models can be done using API or AWS management console. Provide Model name and IAM role.
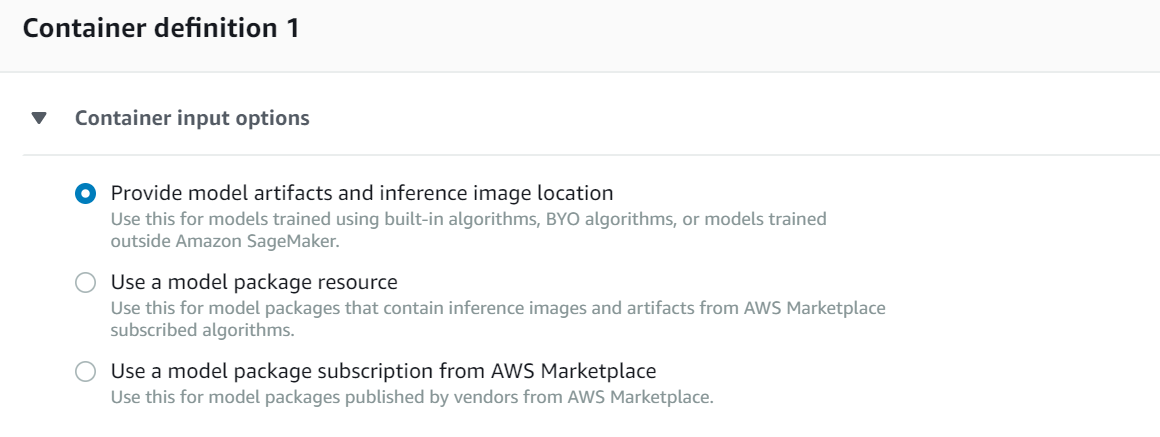
Under the Container definition, choose Provide model artifacts and inference image location and provide the S3 location of the artifacts and Image URI.
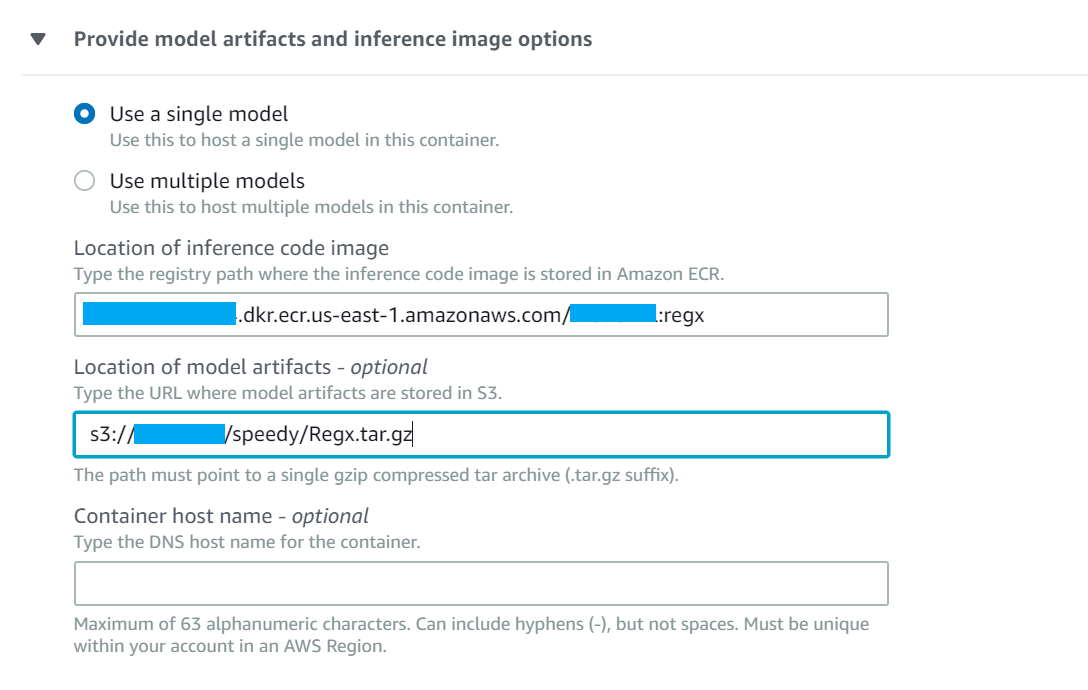
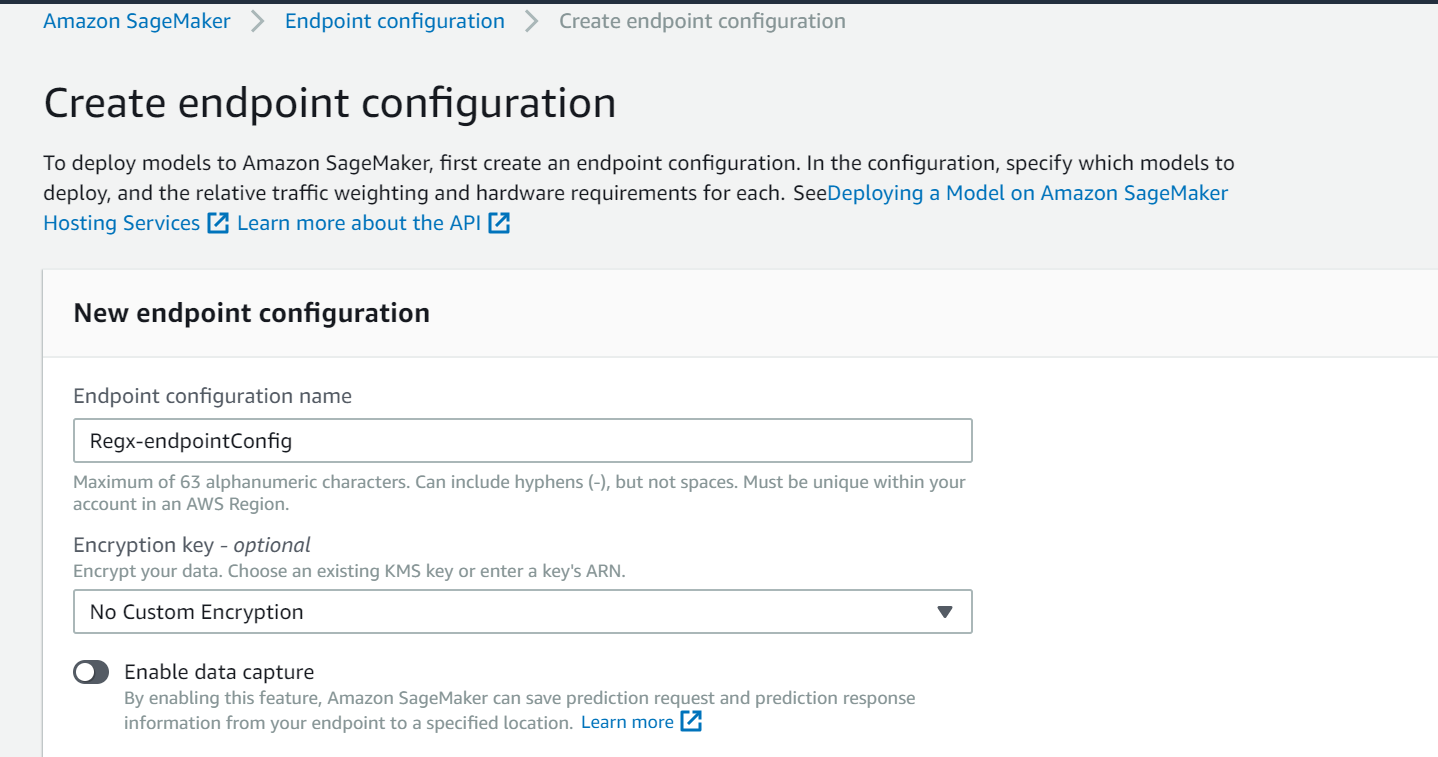
After creating the model, create Endpoint Configuration and add the created model.
When you have multiple models to host, instead of creating numerous endpoints, you can choose Use multiple models to host them under a single endpoint (this is also a cost-effective method of hosting).
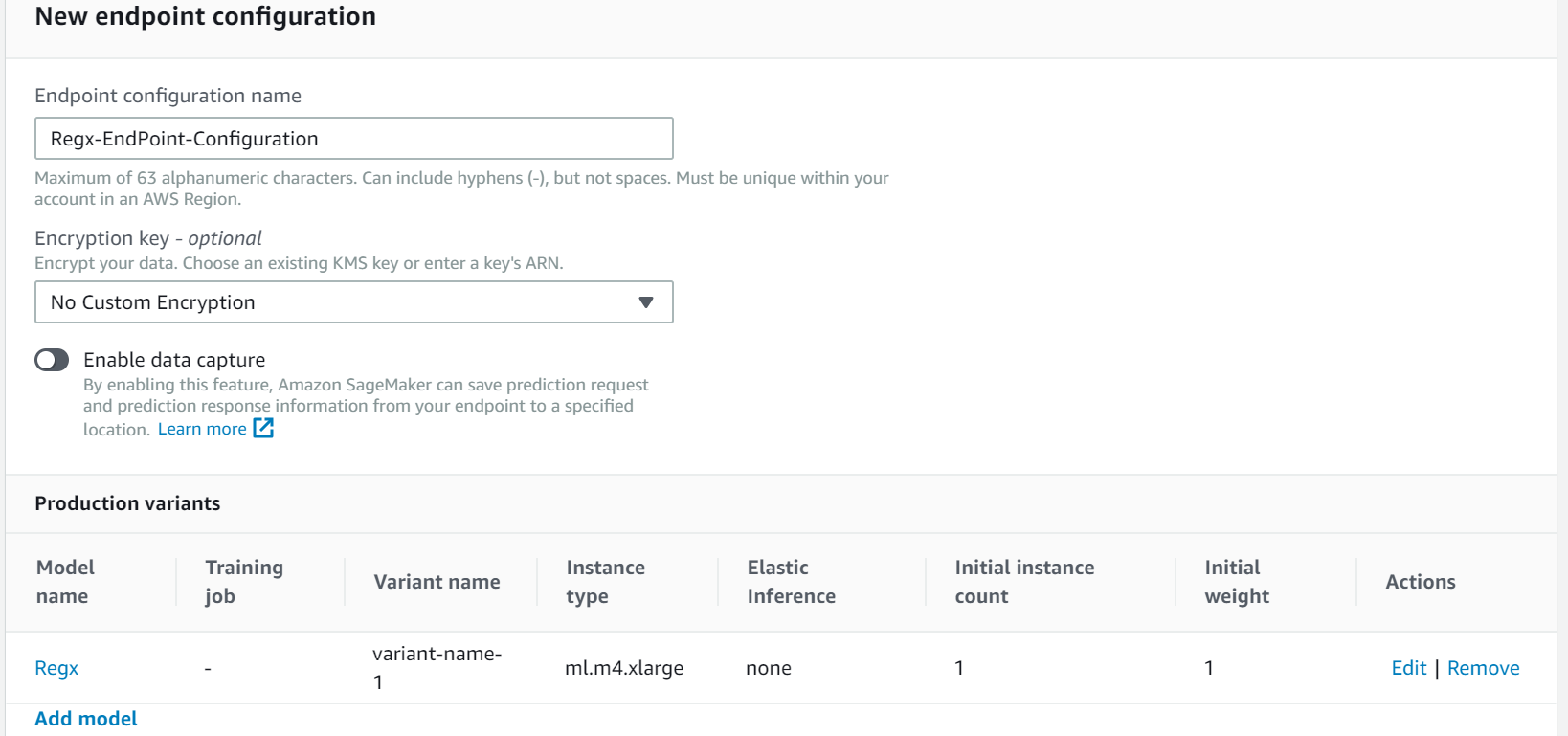
You can change the instance type and instance count and enable Elastic Interface(EI) based on your requirement. You can also enable data capture, which saves prediction requests and responses in the S3 bucket, thereby providing options to set alerts for when there are deviations in the model quality, such as data drift.
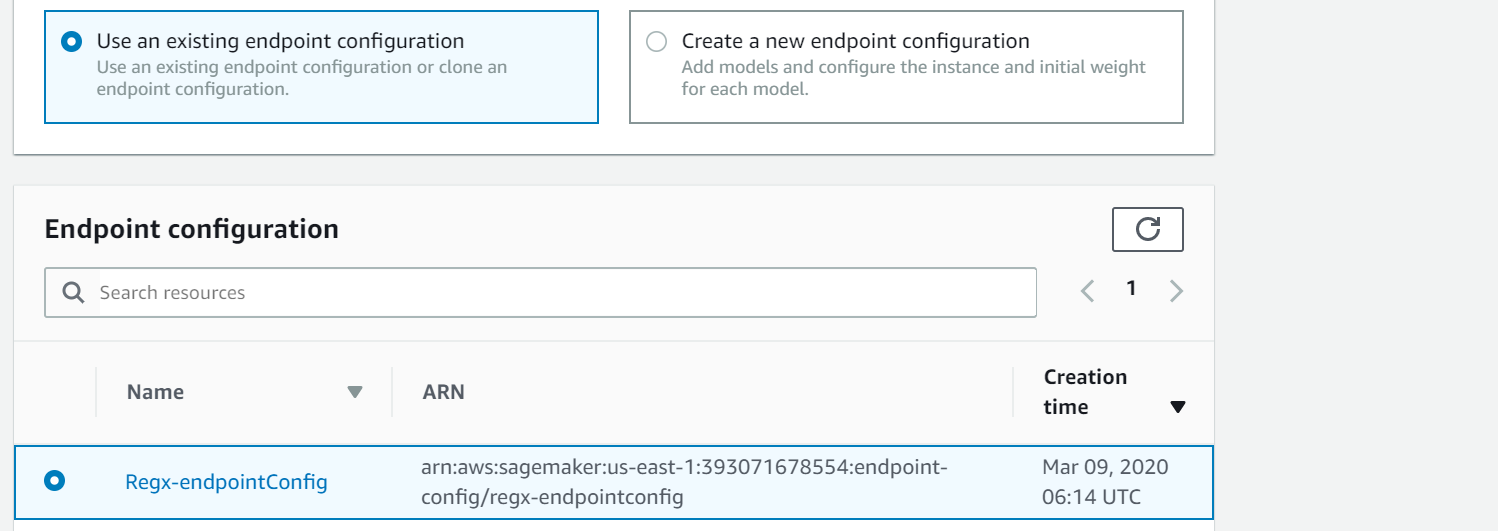
Create Endpoint using the existing configuration
Step 5: Invoking the Model Using Lambda with API Gateway Trigger
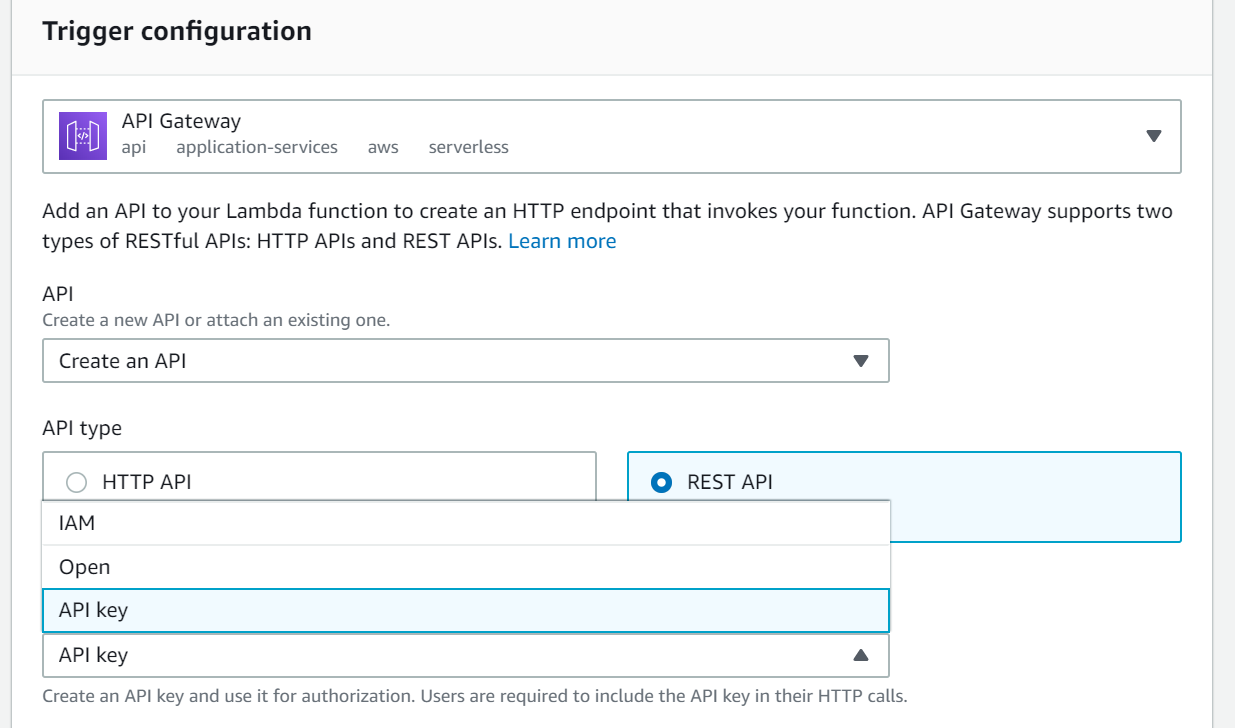
Create Lambda with API Gateway trigger.

In the API Gateway trigger configuration, add a REST API to your Lambda function to create an HTTP endpoint that invokes the SageMaker endpoint.
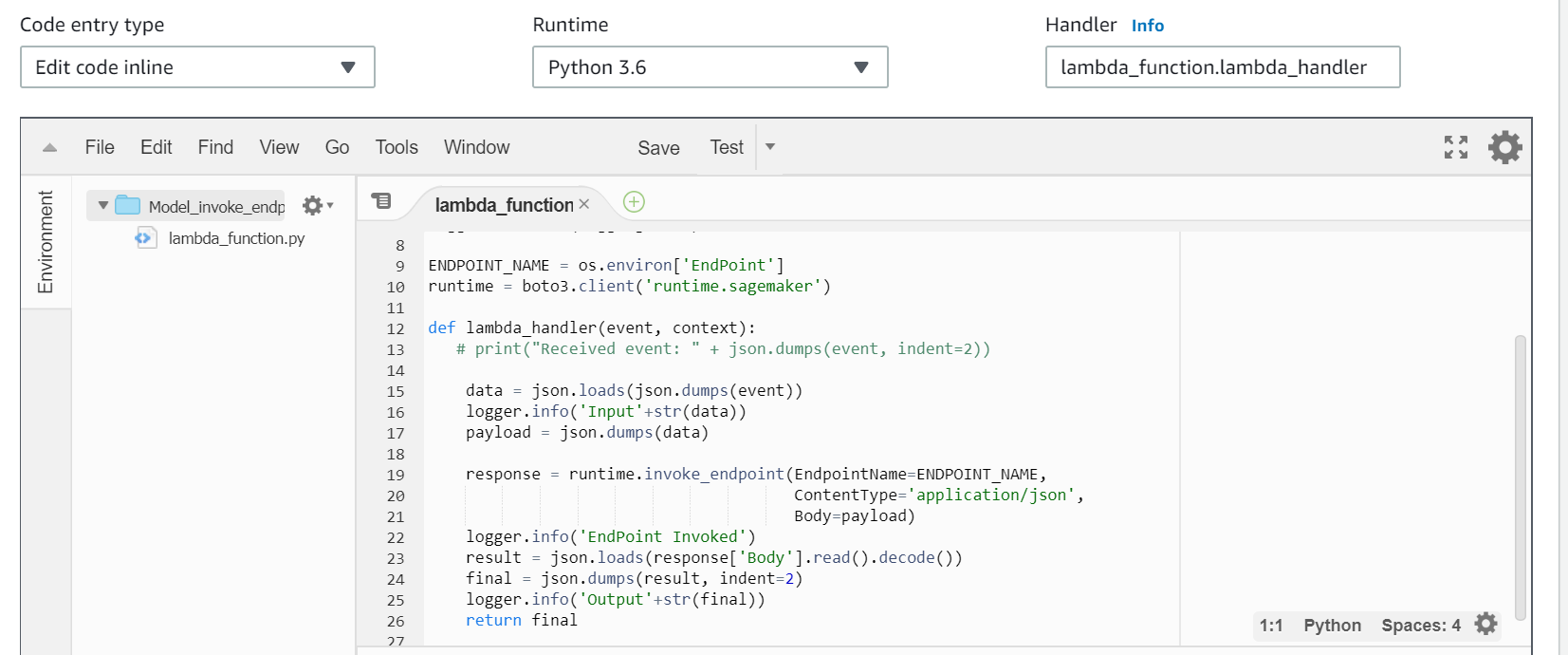
In the function code, read the request received from the API gateway and pass the input to the invoke_endpoint and capture and return the response to the API gateway.
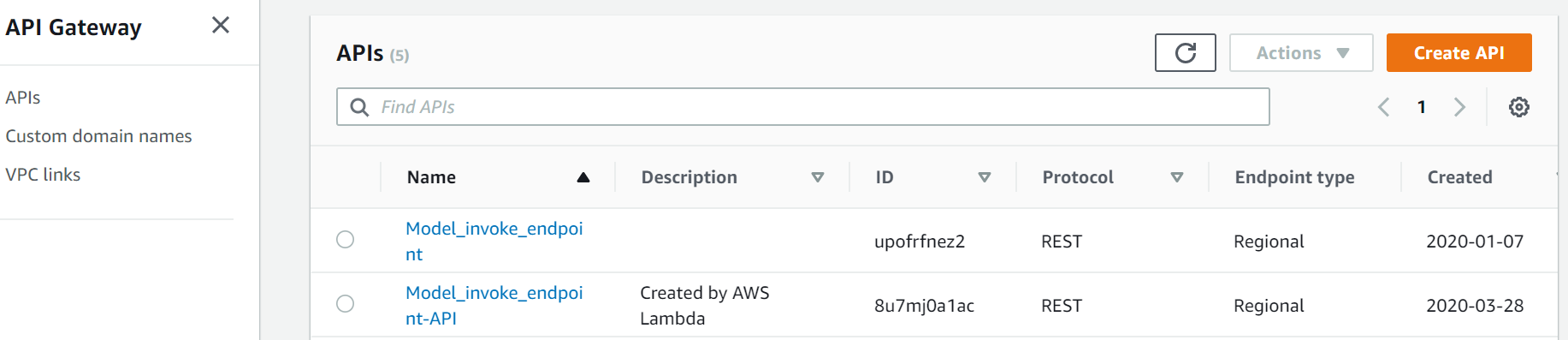
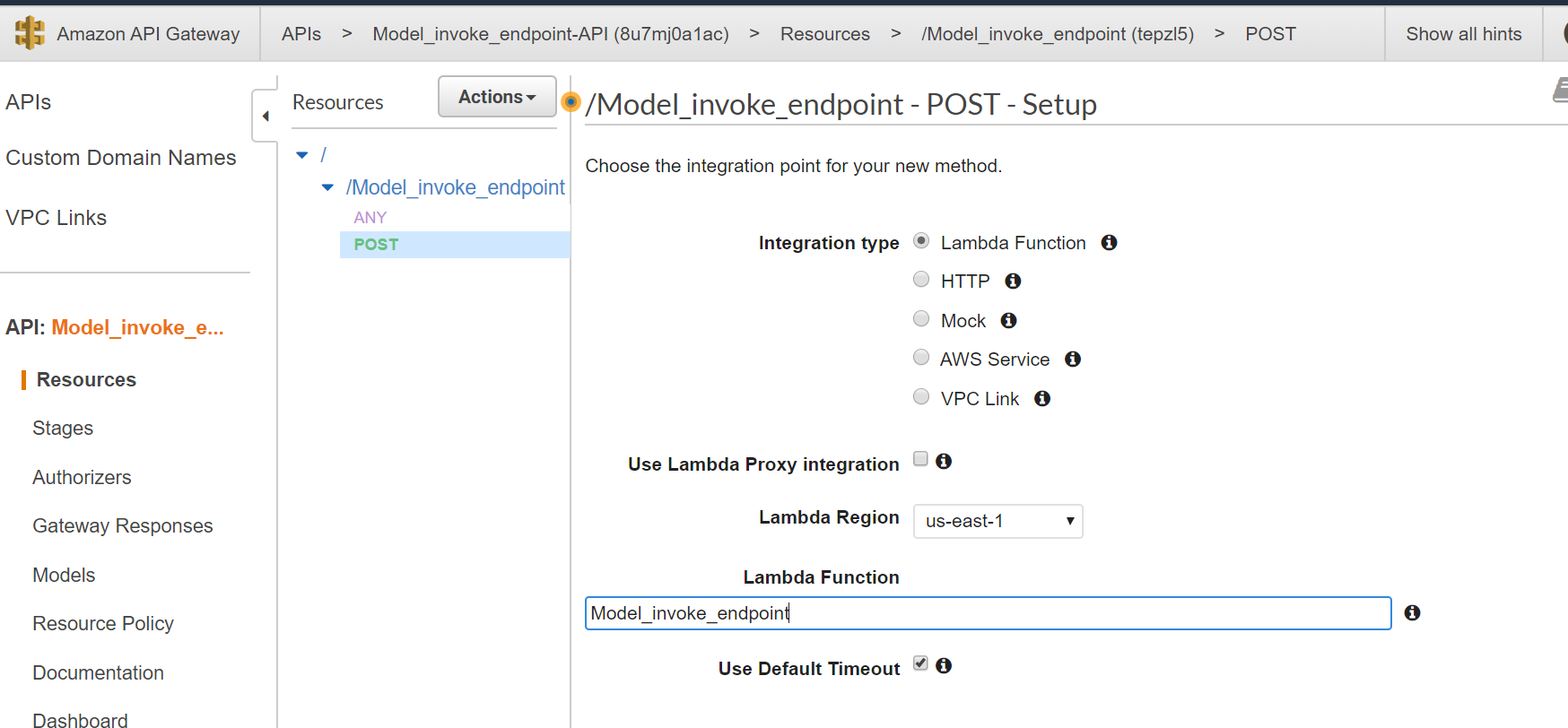
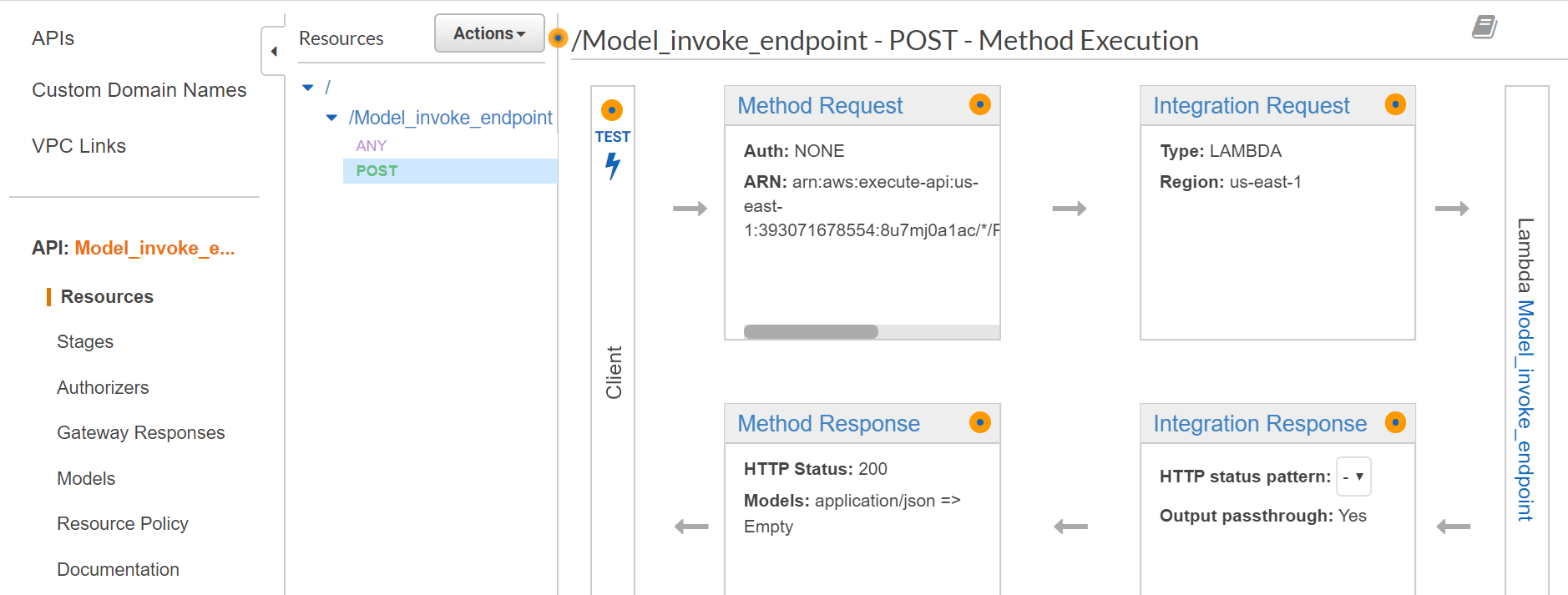
When you open the API gateway, you can see the API created by the Lambda function. Now you can create the method required (POST) and integrate the Lambda function, and test by providing the input in the request body and check the output.
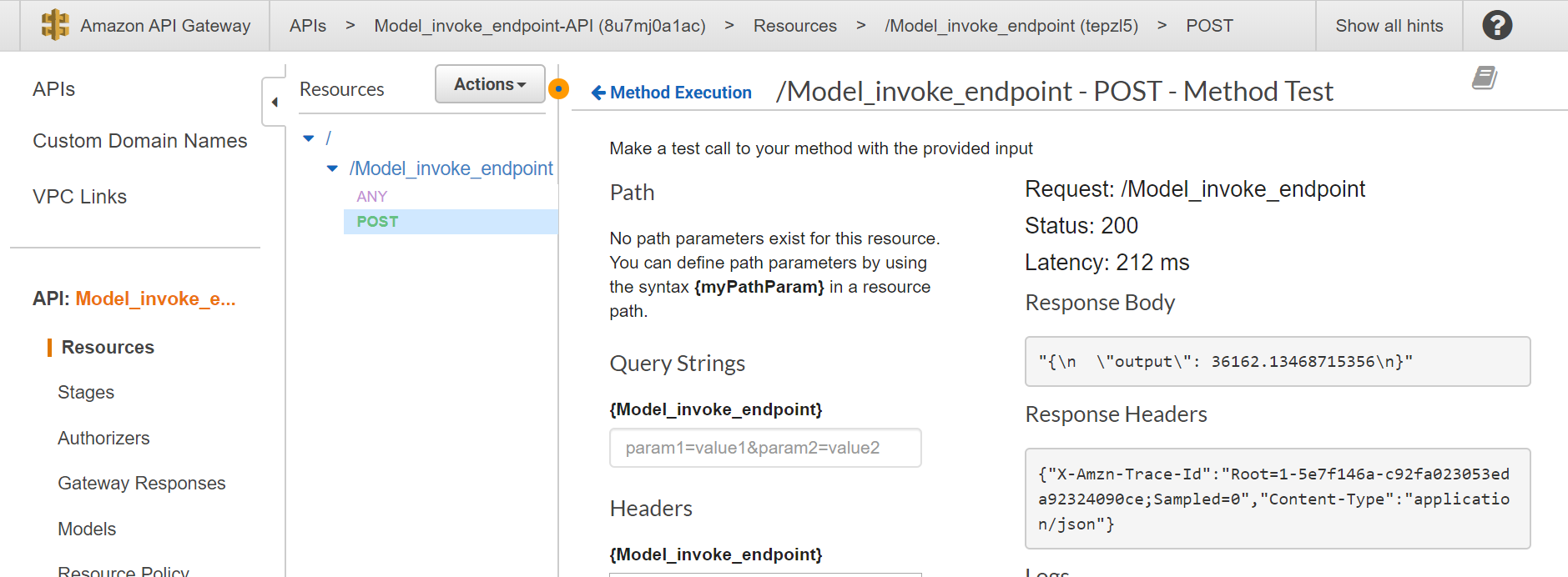
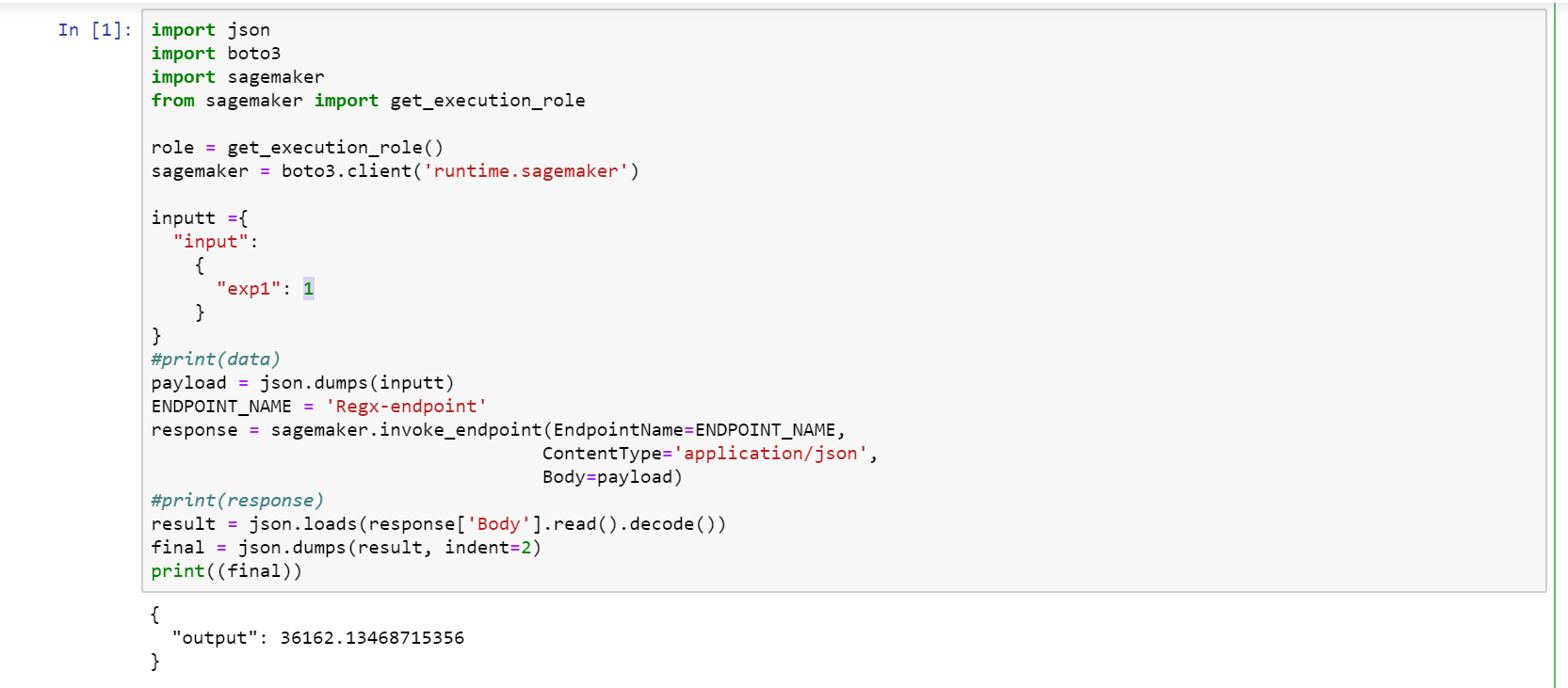
You can test your endpoint either by using SageMaker notebooks or Lambda.
Conclusion
SageMaker enables you to build complex ML models with a wide variety of options to build, train, and deploy in an easy, highly scalable, and cost-effective way. Following the above illustration, you can deploy a machine learning model as a serverless API using SageMaker.




